Introduction
计算机是如何储存数据的?
毫无疑问,对现代计算机来说,数据的基本单元是位(bit),即一位二进制数,值为 0 或 1。那用枯燥的二进制如何描述出文字、图片、视频等丰富多彩的内容呢?
我最初了解计算机相关知识时,这是最吸引我的问题,而它最简洁的答案就是编码。
编码是计算机的基石,其内容十分庞大,本篇文章不可能涉及太多,仅仅介绍字符编码的相关内容。
字符集
字符集 顾名思义就是字符的集合,或者说是数字到字符的映射。在计算机发展的早期 ASCII 渐渐地成为了标准,而现在最常用的字符集则是 Unicode。
ASCII
ASCII 使用一个 byte(1 byte = 8 bits) 代表一个字符,但不使用最高位。所以其表示范围是 0x00 - 0x7F (即十进制的 0 - 127),其中有 33 个不可见字符和 95 个可见字符。
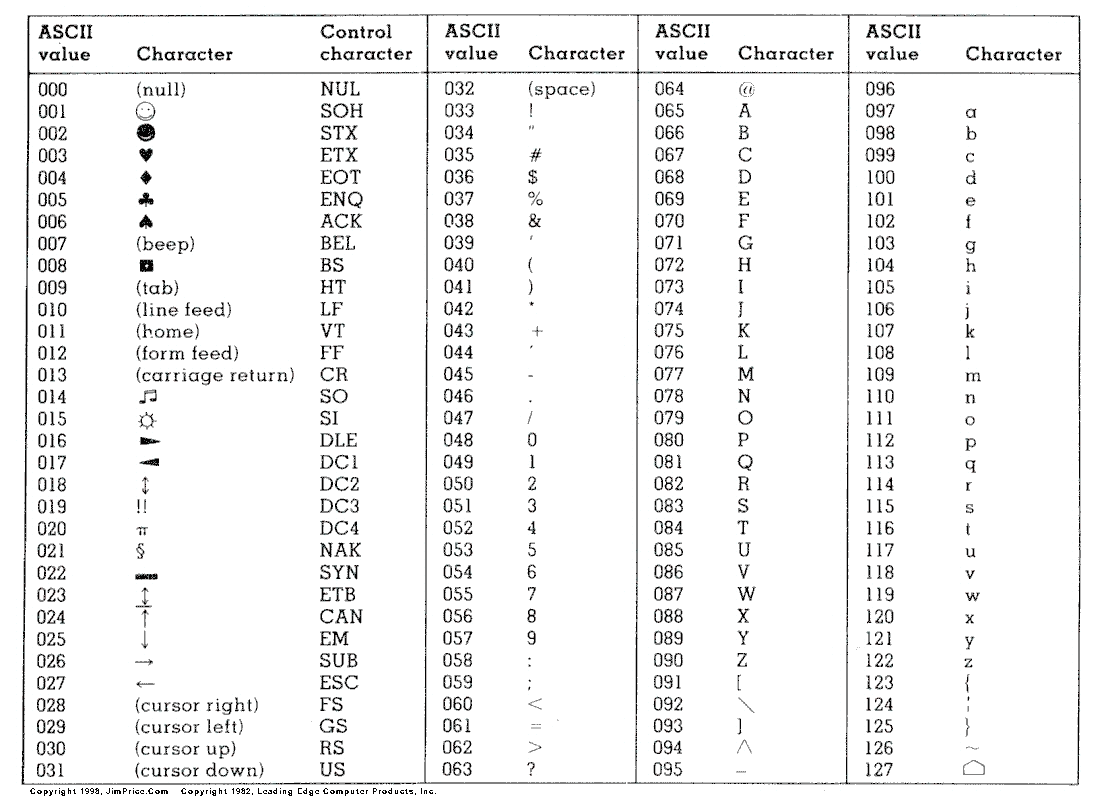
如果在 Python3 中展示的话
1
2
3
4
5
6
>>> ord('a')
97
>>> chr(97)
'a'
>>> chr(ord('a') + 3)
'd'
Unicode
ASCII 只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语。而随着计算机的飞速发展,ASCII 的局限性变得越来越明显。
后面出现了 EASCII (Extended ASCII),即把 ASCII 扩充为 8 位,表示范围是 0x00 - 0xFF(即十进制 0 - 255)。EASCII 解决了部分西欧语言的显示问题,但对更多其他语言依然无能为力。
而现在成为业界标准的 Unicode 对世界上大部分的文字系统(甚至 emoji)进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode 与 EASCII 兼容。
如
1
2
3
4
5
6
>>> ord('a')
97
>>> ord('西')
35199
>>> chr(128514)
'😂'
字符编码
对于单字节字符集来说,字符编码似乎是可有可无的东西,如 Latin-1 ,每个 byte 代表一个字符,毫无歧义和空间浪费。
但对于多字节字符集来说,字符编码的选择就变得十分重要。
比如,有一个数字 32382(0x7E7E),它的长度为两个 bytes,那它到底表示两个 '~'(码值为 126[0x7E]) 还是一个 繾(码值为 32382) 呢?
为了消除歧义,我们可以使用两个 bytes(最初最大的 Unicode 不超出 0xFFFF) 来表示一个字符,这样的确消除了歧义,但却造成了空间浪费 —— 如果所编码字符码值都在 0x00 - 0xFF 范围内的话,就有一半的空间是浪费的。
而在 Unicode 码值范围为 0x00000000 - 0xFFFFFFFF 的今天,我们消除歧义的代价就是最高 75% 的空间浪费!
由于空间浪费大的缺点,最初的 Unicode 并未大规模普及。
直到 UTF-8 的出现。
UTF-8
UTF-8 是一种可变长字符编码,如果 Unicode 字符由 2 个字节表示,则编码成 UTF-8 很可能需要 3 个字节。而如果 Unicode 字符由 4 个字节表示,则编码成 UTF-8 可能需要 6 个字节。
2003 年 11 月 UTF-8 被 RFC 3629 重新规范,只能使用原来 Unicode 定义的区域, U+0000 到 U+10FFFF ,也就是说最多四个字节
UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。
-
如果 Unicode 码值在
0x00 - 0x7F之间,使用 UTF-8 编码后就是其本身 -
如果 Unicode 码值在
0x0080 - 0x07FF之间,码值二进制形式为00000yyy yyzzzzzz的字符 UTF-8 编码为110yyyyy 10zzzzzz
1
2
3
4
5
6
7
8
9
>>> from bitstring import BitArray
>>> chr(0x0101)
'ā'
>>> bin(0x0101)
'0b100000001' # 0b 代表二进制数 ==> 00000001 00000001
>>> 'ā'.encode('utf-8')
b'\xc4\x81'
>>> BitArray(b'\xc4\x81').bin
'1100010010000001' # ==> 11000100 10000001
- 如果 Unicode 码值在
0x000800 - 0x00D7FF | 0x00E000 - 0x00FFFF之间,码值二进制形式为00000000 xxxxyyyy yyzzzzzz的字符 UTF-8 编码为1110xxxx 10yyyyyy 10zzzzzz
Unicode 在范围
0xD800 - 0xDFFF中不存在任何字符
1
2
3
4
5
6
7
8
9
>>> from bitstring import BitArray
>>> chr(0x897f)
'西'
>>> bin(0x897f)
'0b1000100101111111' # 0b 代表二进制数 ==> 00000000 10001001 01111111
>>> '西'.encode('utf-8')
b'\xe8\xa5\xbf'
>>> BitArray(b'\xe8\xa5\xbf').bin
'111010001010010110111111' # ==> 11101000 10100101 10111111
- 如果 Unicode 码值在
0x010000 - 0x10FFFF之间,码值二进制形式为000wwwxx xxxxyyyy yyzzzzzz的字符 UTF-8 编码为11110www 10xxxxxx 10yyyyyy 10zzzzzz
1
2
3
4
5
6
7
8
9
>>> from bitstring import BitArray
>>> chr(0x1f602)
'😂'
>>> bin(0x1f602)
'0b11111011000000010' # 0b 代表二进制数 ==> 00000001 11110110 00000010
>>> '😂'.encode('utf-8')
b'\xf0\x9f\x98\x82'
>>> BitArray(b'\xf0\x9f\x98\x82').bin
'11110000100111111001100010000010' # ==> 11110000 10011111 10011000 10000010
最后,我们再来解码一个 UTF-8 编码的字符串
1
b'\xe5\xad\x97\xe7\xac\xa6\xe7\xbc\x96\xe7\xa0\x81'
二进制形式
1
11100101 10101101 10010111 11100111 10101100 10100110 11100111 10111100 10010110 11100111 10100000 10000001
一共 12 个字节,由 UTF-8 编码规则可得,此字符串一共包含 4 个字符,分别是
1
2
3
4
5
6
7
11100101 10101101 10010111
11100111 10101100 10100110
11100111 10111100 10010110
11100111 10100000 10000001
分别解码为单个字符
1
2
3
4
5
6
7
01011011 01010111 # 0x5b57 ==> '字'
01111011 00100110 # 0x7b26 ==> '符'
01111111 00010110 # 0x7f16 ==> '编'
01111000 00000001 # 0x7801 ==> '码'
最后解码得字符串
1
'字符编码'
当然,除 UTF-8 之外,UTF 家族还有 UTF-16 和 UTF-32 编码(还有下文提到的 UTF-7);除 UTF 之外还有其它用于编码 Unicode 的编码,如 USC 系列;此外还有很多不使用 Unicode 字符集的编码,如我国独创的 GBK 系列编码,但目前最通用的还是 UTF-8。
UTF-8 的主要优点有:
- 通用:采用 Unicode 字符集
- 无歧义
- 相对节省空间:空间浪费范围为
0% ~ 33.3%
关于 UTF-8 具体的优缺点及其他编码相关内容,可以自行查看 Wiki。
后记:历史遗留
虽然 UTF 系列编码已经成了字符编码的标准,但总有一些上古年代的走过来的软件或协议并不支持 UTF,比如 SMTP 最早仅支持 7-bit encoding 即 ASCII。
那在这种情况下如何使用非 ASCII 字符呢?
当然是把 8-bit bytes 编码到 7-bit bytes,其中最常用的编码就是 Base64。
Base64
Base 家族常见的有 Base64, Base32, Base16 三种编码,他们的编码规则大致相同,最常用的是 Base64 编码。
Base64 的编码规则简单来说就是把三个字节一共 3 x 8 = 24 个字节拆成 四个字节。
1
wwwwwwxx xxxxyyyy yyzzzzzz ==> 00wwwwww 00xxxxxx 00yyyyyy 00 zzzzzz
当字节总数不能被 3 整除,在后面补 0,再根据缺少的字节数在编码后文本添加 1 到 2 个 =
- 剩 1 个字节
1
2
yyyyyyzz ==> 00yyyyyy 00zz0000
# 最后以 == 结尾
- 剩 2 个字节
1
2
3
xxxxxxyy yyyyzzzz ==> 00xxxxxx 00yyyyyy 00zzzz00
# 最后以 = 结尾
那如何表示拆开后的字节呢?
我们可以看到,由于最高的两位用 0 填充,每个字节的取值范围是 0 - 63,base64 规定,0 - 63 分别对应
1
2
3
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
1
2
3
4
5
6
7
>>> import base64
>>> base64.b64encode('字符编码'.encode())
b'5a2X56ym57yW56CB'
>>> base64.b64encode('字符编码X'.encode())
b'5a2X56ym57yW56CBWA=='
>>> base64.b64encode('字符编码XX'.encode())
b'5a2X56ym57yW56CBWFg='
即
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
'字符编码'
==>
b'\xe5\xad\x97\xe7\xac\xa6\xe7\xbc\x96\xe7\xa0\x81'
==>
11100101 10101101 10010111
11100111 10101100 10100110
11100111 10111100 10010110
11100111 10100000 10000001
==>
00111001 00011010 00110110 00010111
00111001 00111010 00110010 00100110
00111001 00111011 00110010 00010110
00111001 00111010 00000010 00000001
==>
'5a2X56ym57yW56CB'
base 系列编码并不属于字符编码,他们主要用于把一串“无意义的”八位二进制字节编码为可见 ASCII 字符。base64 大概浪费了 25% 的空间,base32 是 37.5%,base16 是 50%。
“无意义” 是指,base 编码可编码任意二进制而无需知道其意义。
UTF-7 则是 UTF16 和 Base64 的组合产物,其内容可以自行搜索。
最后我有一个问题,如果从节省空间的角度考虑,为什么不用 base128 呢?